Scaling Analytics with dbt @ Decathlon

Over the past year, I’ve led a deep transformation of how the Supply Data team uses dbt — scaling it from a patchy, under-optimized setup into a powerful, cost-efficient, and well-governed analytics pipeline running on Databricks.
👉 Here’s how we went from “it works” to “this scales”.
From dbt Cloud to dbt Core + Airflow
The first major turning point was migrating from dbt Cloud to dbt Core orchestrated via Airflow.
This gave us the control and flexibility we needed to handle a growing number of models, contributors, and use cases — while cutting licensing costs [*].
When we decided to move from dbt Cloud to dbt Core + Airflow, we had two choices:
- Lift-and-shift: migrate everything as-is and maybe refactor later,
- Rebuild intentionally: take the opportunity to rethink architecture and deliver org-wide value from day one.
I chose the second path. Our dbt Cloud jobs were too consolidated (dozens of models in one DAG), and the current structure just wouldn’t translate cleanly into Airflow.
I also wanted to jump on this opportunity to make something that would help all people struggling with Airflow in the organization.
Of course, we explored Cosmos — an open-source dbt-to-Airflow adapter — but ultimately opted out because of performance overhead. On our shared Airflow infrastructure, Cosmos added latency and complexity we couldn’t afford.
So we built our own: the Factory — a lightweight Airflow library tailored for analytics use cases. Designed for all Decathlon Analytics people (i.e. DA / BI / AE / DE i.e. > 250 people), it combined the flexibility of Python-native DAGs with opinionated defaults:
- Native alerting via Google Chat, Slack, and Email,
- Tableau orchestration (yeah, automated extracts!),
- Smart dbt test surfacing, so stakeholders could act early,
- Event-driven scheduling to avoid wasteful runs,
- Variable passing & exposure logging to improve auditability and observability.
This orchestration layer quickly became our backbone — and a springboard for serious performance and cost wins.
[*] Of course, you still have to pay for Airflow, but since at Decathlon Airflow instances are mutualized, you mechanically decrease your cost compared to an Analytics only solution like dbt Cloud.
30% Cost Reduction, 600% Runtime Improvement
After establishing a robust foundation, we turned to efficiency. Through smarter scheduling, pipeline optimization (think incremental / microbatch runs & var scheduling), and a ruthless focus on unnecessary test/runs, we:
- Cut dbt costs by ~30%,
- Improved our CI/CD runtime by ~600% (from 1 hour down to ~10 minutes)
The difference was night and day: faster dev loops, fewer failed deployments, and a clearer path to production.
Building a Culture of Data Engineering Excellence
Scaling dbt is about more than infra. It’s about people.
We trained and coached 10 Data Analysts, 5 Data Scientists, and 3 Data Engineers to write performant, testable dbt code using best practices — so they could own their transformations, not just request them.
We delivered workshops on:
- STAR and Snowflake modeling patterns (and how to use them well),
- Modular, DRY SQL and the logic of reusable macros,
- Effective testing strategies: data tests, unit tests, and CI validation
- How to manage environments (dev, preprod, prod) safely
We reviewed pull requests, co-designed transformations, and made sure everyone was equipped to deliver reliable, auditable outputs — independently.
This training would make it so that everyone who wanted to participate to this dbt journey would be able to. And the response was enthusiastic — adoption accross analysts surged.
dbt sparked so much interest on the DA / DS side, that, after careful consideration, we decided to let them have ownership of the aggregate layer (i.e. where we prep data for BI / Analysis work).
This meant that responsibility was divided as such:
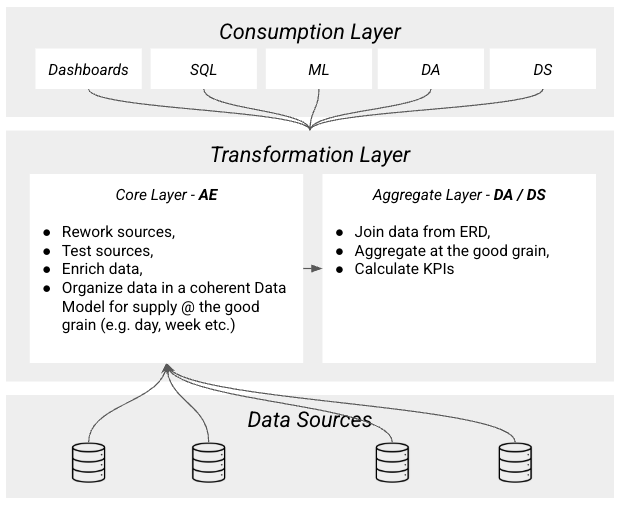
- AE were responsible for:
- Organising the data: this meant create an ERD, since we decided to ditch the OBT for the Core Layer & go for Kimball instead,
- Test the data,
- Create frameworks for everybody to work with (i.e. testing, Airflow etc.)
- DA / DS were responsible for:
- Understanding the core layer & how to use it,
- Focus on making simple joins & aggregations
Deliverables That Moved the Needle
Our work wasn’t theoretical. Tangible outcomes included:
- A restructured data model built on STAR/Snowflake architecture
- Defined KPIs and strategy for the analytics team
- Massive cost and performance optimizations across the board
- Clear technical guidance for scaling dbt responsibly
- A sustainable dbt practice that scales beyond individuals
Lessons Learned
If I had to boil it down, scaling dbt for analytics at the org level comes down to a few core principles:
- Model for scale — STAR/Snowflake modeling isn’t old school, it’s maintainable,
- Own your orchestration — understand what’s going on & take ownership,
- Test smart, not just hard — unit tests + CI feedback loops = confident releases,
- Cost isn’t an afterthought — it’s at the core of Data Engineering,
- Teach, don’t gatekeep — upskilled analysts == a multiplier on delivery.
Conclusion
As my first year at Decathlon comes to an end, one thing is clearer than ever: scaling dbt isn’t just about performance, faster pipelines or cutting costs.
It’s also about enabling more people to safely build better data products — driving faster decisions, more confident experimentation, and scalable governance.
In other words: enabling better business outcomes through better data engineering practices & influence.
Struggling with your data analytics project? Let's fix it together.
I help teams solve tough data problems — fast.