Supercharging dbt: why dbt + your orchestration layer = one app, not two (2/3)

This article is part of a series of 3 articles in which I explore what works / breaks at scale with dbt and how to fix it.
If you're interested, here is the previous article below:

apps . For instance, I used to think as
Airflow and dbt as two separate tools: one for orchestration and the other for data processing.However, having now (way) more experience, I realise that it's really not the case: an orchestration layer and a transformation layer cannot exist without the other - it just wouldn't make any sense in any serious production-grade setup, right ?
This is why I advance this hot take:
dbt + Airflow is actually 1 data app, each part with different strength, not 2 unrelated tools that you patch together.👉 Let's see why !
The Disjointed Mental Model
When I begin working for a client using dbt, the first thing I always check first is how they are handling their orchestration layer.
Based on this, and experience, I can usually get a read on how they think about orchestration:
- No production-grade orchestrator: either the scale doesn't demand it (early-stage startups), or there's a gap in how they value orchestration.
- Production orchestrator, but just triggering
dbt run -s <something>: they've got the tooling, but they're not getting much out of it yet. - Atomic tasks with proper alerting: now we're talking. They're treating orchestration as operations, not just scheduling.
- Add observability and a test framework; the full picture: orchestration as a first-class part of the platform.
What really separates each of these situation is not the tech knowledge but how each team perceive their orchestration layer: something they "need to go through" or a way to ensure operations are running as smoothly as they should.
That's why I actually think that Data teams should benefit to think as transformation and orchestration are two sides of the same coin: their data app.
Note: of course, the level of "orchestration" your team needs completely depends on what scale you're working with. Do not overengineer this because it's the "right thing to do" - take into account your needs and then create your data platform, not the other way around.
You're always integrating your transformation layer with your orchestrator
If we continue of the dbt / Airflow example, the best teams I've seen create DAGs dynamically based on the dbt compilation results (manifest.json for instance).
This means that dbt creates your transformation graph, and Airflow creates DAGs based on the exact same logic.
As such Airflow & dbt share the exact same logging, metadata & execution flow.
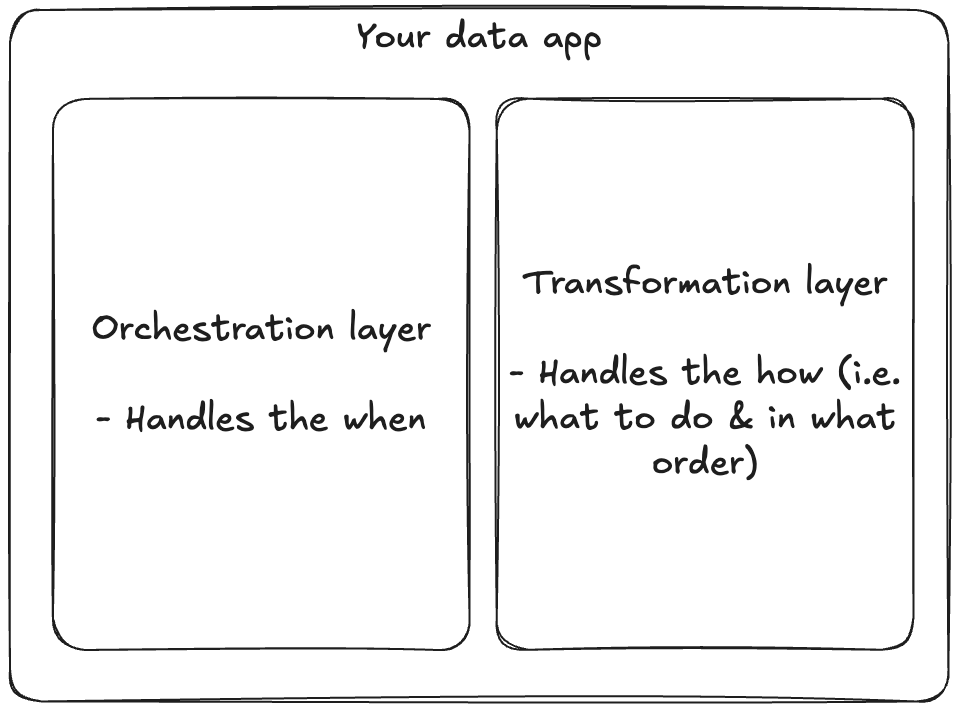
Also, dbt & Airflow are complementary - they do not handle the same part of the data app at all:
- Airflow handles
retries,workflow management @ scale,queuingetc. - dbt handles only
sql tranformations&warehouse management
dbt without an orchestration layer, like Airflow or Dagster, or GitHub Actions even, does not make any sense as it means that you would always trigger your DAGs locally, thus completely destroying the impact of having a reliable transformation layer.
As such, you're always integrating the first with the second: isn't that exactly what a data app is ?
Note: you could replace dbt with sqlmesh or raw SQL; Airflow with any other orchestration tool, the idea is still the same.
A better mental model
As such, I would like to propose a better mental model, that I think could benefit to Data Teams that only see orchestration as a pain that needs to be dealt with:
This means that what you see in dbt should be reflected in Airflow and vice-versa. Kind of like if your orchestration layer was the front-end of your transformation layer and dbt was your back-end.
This also means that you should see Airflow as a real front-end i.e. a way to understand what's going on with your pipelines. It's where your logs should be stored (as much as possible), your failures / successes, your specific orchestration business logic etc.
This means your orchestration should be your Single Source Of Truth (SSOT) for what's going on in your data app and it should be self-sufficient (at least up unto a point).
This also means that any "observability" dashboard you're using should be iso with what you're seeing in Airflow. If not, you'll have problems in the long run, trust me.
Why this approach makes more sense
Let's dive into the pros and cons of such an approach !
Firstly, having your orchestration layer as the front-end of your pipelines decreases context-switching. This means that your team understand your tool well, you don't have to look into 3 pages of log everytime you have a bug etc.
This also means that your team will be more efficient. Bugs will take less time to be handled, alerting will be from Airflow only, thus decreasing mental overload etc.
Secondly, as I explained before, having a SSOT for your pipeline logic will make easier the tracking of SRE KPIs, thus making everybody more in line with the team strategy:
- No more wondering if your MTTR or Uptime is OK
- All teams calculate the SRE KPIs the same way
As Data / Analytics Engineers, we're trying to get to business teams' alignments in how they perceive / calculate business KPIs.
Why shouldn't we be the first to think about our owns ?
Finally, this approach makes team ownership easy to handle as team would be now responsible of DAGs (not models).
This makes teams think in terms of use cases - and having a simplified mental model on your orchestration layer makes migration from team to others easier as everybody sees this layer the same way.
The main caveat of this mental model is how rigorous it is to maintain: if all teams have to have the same mental model over what Airflow is, this means that you should have pretty hard driven guidelines (i.e. rules to contribute to the repo) both on Airflow & dbt.
The other, is it means potentially thousands of tasks, slower DAG parsing, and more complex debugging when something goes wrong at the orchestration layer itself.
For some team, this is too much, for other it's the norm. You do you 😄
Let's talk operations: how to do this in practice
The main things you'd have to do if you want to integrate this mental model in your team are:
- Co-locate Airflow and dbt in 1 monorepo
- This makes things easier in the long run
- A common objection to monorepos is that they don't scale. But Google runs one of the largest monorepos in existence: so scale itself isn't the problem.
- For most data teams, co-locating Airflow and dbt simplifies versioning and deployment without introducing meaningful complexity.
- Use dynamic DAGs
- Mostly using
manifest.jsonparsing creating 1 dag based on the tagging / exposure approaches- Tagging = you tag models you need in your pipeline and then run
dbt run -s tag:your_tag - Exposure = you specify exposure of a pipeline and then run
dbt run +exposure:your_exposure
- Tagging = you tag models you need in your pipeline and then run
- Personally I prefer the tagging approach as this makes sure that each teams knows exactly what is run & it's not decided by dbt - but be aware that this method requires more work than the other.
- Mostly using
- Version control both together
- Your CI/CD should automatise all the things you need to know in your project:
- Can Airflow parse your dbt project ?
- Is your dbt project up to your standards ? (using
dbt-scorefor instance) - Is your Airflow project up to your standards (using a tool like
rufffor instance) - Deploying
dbt-docs& your Airflow documentation - etc.
- Your CI/CD should automatise all the things you need to know in your project:
- Use Airflow
data_intervalvariables to handle incremental scheduling- As explained in the first article, Airflow
data_intervalare one of the best Airflow features - Use them as vars in your dbt project to make sure all your incremental pipelines are idempotent & deterministic
- As explained in the first article, Airflow
OK - this seems a lot of work, and you're right, it is.
Luckily for us, the kind of problem you'd have if you wanted to put this approach in practice has been working on time and time again:
- That's why I recommend you use an open-source library like Astronomer's Cosmos to handle all the boring stuff,
- You'd still have to create Webhook Alerting and some observability layer but the Airflow / dbt interface would be way easier to handle

Astronomer's Cosmos - Presentation

Astronomer's Cosmos - GitHub
Conclusion: think integration, not isolation
dbt + Airflow form a single, cohesive system. When you stop treating them as separate tools that happen to coexist and start viewing them as complementary halves of one data platform, everything clicks into place.
Your DAGs will become cleaner. Your deployments will become simpler.
This "one app" mindset isn't just philosophical. It means shared configuration, unified logging, coordinated versioning, and deployment pipelines that treat your orchestration and transformation layers as a single deployable unit.
The result is less friction, fewer integration headaches, and a development experience that actually scales with your team.
If you're still managing Airflow and dbt as loosely coupled strangers in your stack, consider this your invitation to refactor.
Start with your mental model, then let this guide your tooling choices and deployment strategy. I guarantee the payoff isn't incremental: it's transformational.
Struggling with your data analytics project? Let's fix it together.
I help teams solve tough data problems — fast.